Case Study:
Real-time IoT data platform at a scaling automotive startup
Navigating complex paths to resolution, from optimizing data reliability to Product-led growth initiatives.
Context
Company stage
Early-stage, venture-backed startup in active scale-up mode. Small, fast-moving team operating under startup constraints with enterprise-grade platform expectations.
Industry
Automotive & connected vehicles / IoT
Product type
Developer tools for real-time streaming data
What was at stake
I was brought into a high-growth, high-stakes platform initiative where infrastructure reliability and product expansion were both urgent, and both under-resourced.
The Problem
Rapid user and data growth was exposing platform reliability issues at the infrastructure level - clustering, load balancing, and node overwhelm, were becoming active risks to SLA commitments. Addressing them required focused engineering effort.
At the same time, the platform's developer-facing layer - SDKs, onboarding, language support, observability tooling - was still maturing and needed investment to support expansion to new enterprise clients. Both workstreams were genuinely urgent. Choosing one meant real consequences for the other. There was no clean sequencing and no additional resources to draw on.
The Constraints
Technical: Platform reliability issues were complex and required deep investigation before any solution could be implemented — multiple architectural approaches had to be evaluated before a path forward was clear.
Organizational: Small startup team. Engineering bandwidth was shared across platform infrastructure and product development with no dedicated split. Every prioritization decision had direct opportunity cost.
Resource: Startup-scale headcount with enterprise-scale platform demands. No ability to staff up quickly to run workstreams independently.
Time: SLA obligations to enterprise clients made reliability non-negotiable. Growth targets made developer experience non-deferrable. Both had real deadlines attached.
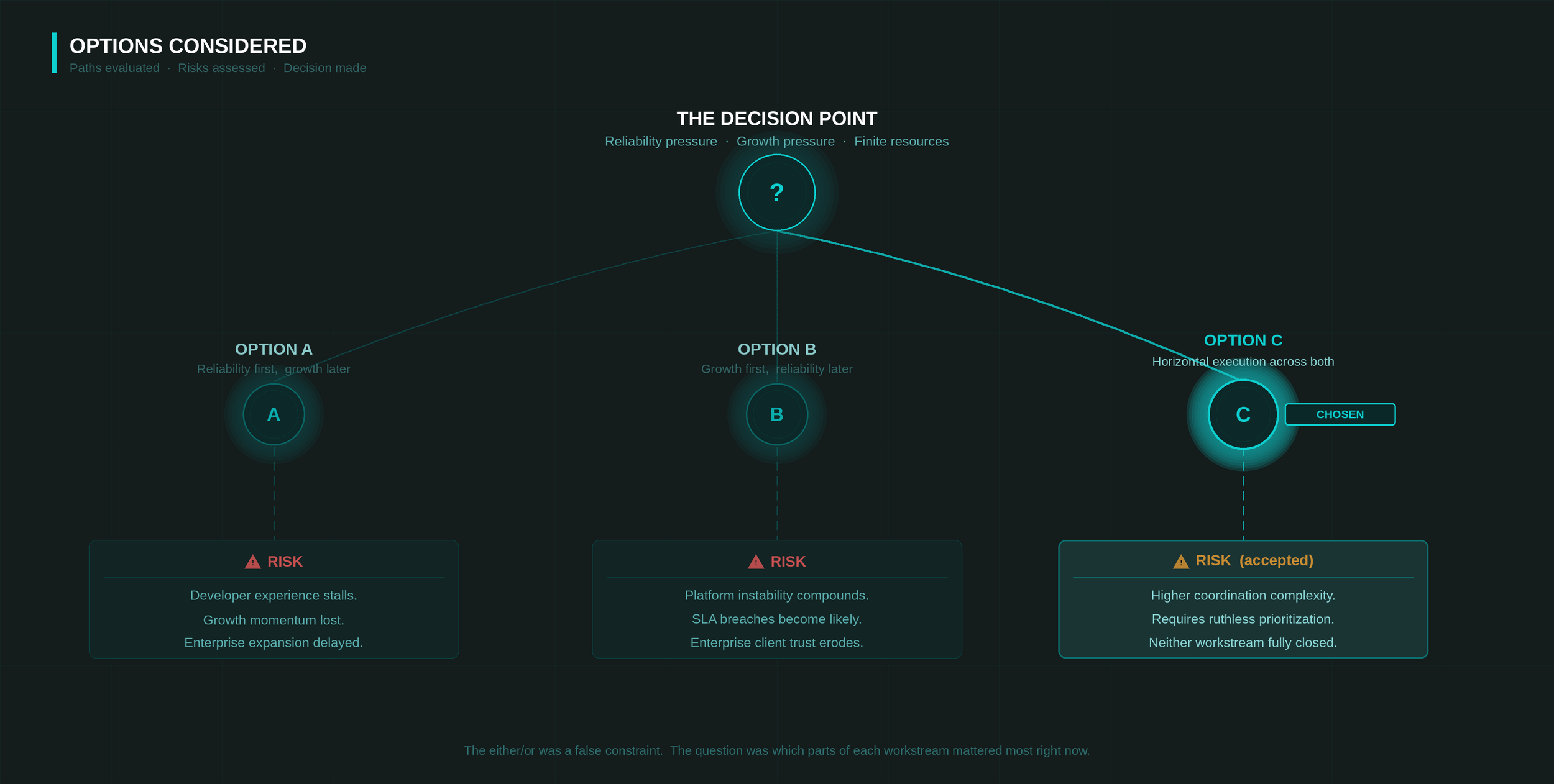
How I evaluated options
Options A and B both assumed a false binary, that the two workstreams couldn't coexist. In practice, not all reliability work was equally urgent, and not all growth work was equally impactful. The real question wasn't which workstream to choose, but which specific components of each were truly blocking versus which could wait.
Mapping the workstreams horizontally - by priority within each, not by workstream - revealed a viable parallel path. The most critical clustering investigation and the most impactful SDK improvements could both be executed in the same cycle without fully competing for the same resources.
My Verdict
Option C.
The most critical infrastructure work and the most impactful developer-facing improvements ran in parallel within the same cycle. The goal was never full completion of either; it was the right progress on both.
Why I chose this
The either/or framing was a false constraint. Both workstreams had components that were genuinely urgent and components that could be phased. Executing horizontally across the highest-priority items in each was more valuable than fully completing one while the other deteriorated.
What I intentionally didn't do
Treat this as a portfolio balancing exercise & spreading effort evenly across both workstreams regardless of actual priority. The horizontal approach required hard calls within each workstream about what mattered most right now.
Risks I accepted
Neither workstream would be fully resolved in the short term. I accepted the incompleteness explicitly. The goal was forward momentum on both fronts, not closure on either.
Decision & Rationale
Outcome
What changed
The most critical infrastructure improvements were scoped, investigated, and implemented. On the developer-facing side, key platform components advanced materially, moving from earlier to later stages across the release lifecycle.
What moved forward
Usage grew at an average of 110% month-over-month. The platform ultimately powered real-time data processing for over 15 million connected vehicles worldwide. The SDKs became the primary developer touchpoint for enterprise clients building vehicle-integrated applications.
What I'd do differently
The prioritization logic within each workstream was worked out informally and in real time. Establishing a clearer shared framework for how to rank items within each workstream earlier, rather than making those calls ad hoc, would have reduced ambiguity and made the parallel execution easier to communicate to stakeholders.
Applicability
If I were dropped into this problem today as a consultant, the first move would be to challenge the either/or framing before any prioritization conversation happens. The instinct to sequence - pick one thing, finish it, then start the next - is deeply embedded in how most teams think about resource constraints. But it often rests on the assumption that both workstreams are monolithic, when in reality both have internal priority gradients.
The more useful question is: what is the single most important thing to move in each workstream, and can those two things coexist in the same execution cycle? Usually, they can.
The broader pattern - reliability pressure colliding with growth pressure at a scaling startup - is one of the most common and most consequential tensions in early-stage product work. How you resolve it shapes not just the quarter, but the trajectory of the platform. Getting the framing right before committing to a path is where most of the value gets created or destroyed.
< Previous | Case Studies Home | Next >